|
Jon Barron I'm a principal research scientist at Google DeepMind in San Francisco, where I lead a small team that mostly works on NeRF. At Google I've worked on Glass, Lens Blur, HDR+, VR, Portrait Mode, Portrait Light, Maps, and Shopping. I did my PhD at UC Berkeley, where I was advised by Jitendra Malik. I've received the PAMI Young Researcher Award. |

|
ResearchI'm interested in computer vision, deep learning, generative AI, and image processing. Most of my research is about inferring the physical world (shape, motion, color, light, etc) from images, usually with radiance fields. Some papers are highlighted. |


|
Image Generators are Generalist Vision Learners
Valentin Gabeur, Shangbang Long, Songyou Peng, Paul Voigtlaender, Shuyang Sun, Yanan Bao, Karen Truong, Zhicheng Wang, Wenlei Zhou, Jonathan T. Barron, Kyle Genova, Nithish Kannen, Sherry Ben, Yandong Li, Mandy Guo, Suhas Yogin, Yiming Gu, Huizhong Chen, Oliver Wang, Saining Xie, Howard Zhou, Kaiming He, Thomas Funkhouser, Jean-Baptiste Alayrac, Radu Soricut arXiv, 2026 project page / arXiv Reducing monodepth, normals, and semantic segmentation tasks to a single RGB-image-prediction task and fine-tuning an image generator (Nano Banana Pro) beats or ~matches specialized models. |

|
GR3EN: Generative Relighting for 3D Environments
Xiaoyan Xing, Philipp Henzler, Junhwa Hur, Runze Li, Jonathan T. Barron, Pratul P. Srinivasan, Dor Verbin SIGGRAPH, 2026 project page / arXiv Distilling the outputs of a video-to-video relighting diffusion model into a 3D reconstruction enables controllable 3D relighting of room-scale scenes. |

|
ZipMap: Linear-Time Stateful 3D Reconstruction via Test-Time Training
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T. Barron, Noah Snavely, Aleksander Hołyński CVPR, 2026 project page / arXiv / code Test-time training lets you quickly compress an entire image collection into a compact model and thereby achieve linear-time 3D reconstruction. |


|
Radiance Meshes for Volumetric Reconstruction
Alexander Mai, Trevor Hedstrom, George Kopanas, Janne Kontkanen, Falko Kuester, Jonathan T. Barron CVPR, 2026 (Highlight) project page / arXiv Parameterizing a scene with a Delaunay tetrahedralization and a neural field yields a scene representation that is accurate, fast to render, easy to edit, and backwards-compatible. |


|
NExF: Learning Neural Exposure Fields for View Synthesis
Michael Niemeyer, Fabian Manhardt, Marie-Julie Rakotosaona, Michael Oechsle, Christina Tsalicoglou, Keisuke Tateno, Jonathan T. Barron, Federico Tombari NeurIPS, 2025 project page / arXiv Learning a neural field that optimizes exposure for each 3D point enables high-quality 3D-consistent view synthesis despite extreme exposure variation during capture. |

|
Bolt3D: Generating 3D Scenes in Seconds
Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, Aleksander Holynski, Ricardo Martin-Brualla, Jonathan T. Barron, Philipp Henzler ICCV, 2025 project page / arXiv By training a latent diffusion model to directly output 3D Gaussians we enable fast (~6 seconds on a single GPU) feed-forward 3D scene generation. |

|
EVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis
Alexander Mai, Peter Hedman, George Kopanas, Dor Verbin, David Futschik, Qiangeng Xu, Falko Kuester, Jonathan T. Barron, Yinda Zhang ICCV, 2025 (Oral Presentation) project page / arXiv Raytracing constant-density ellipsoids yields more accurate and flexible radiance fields than splatting Gaussians, and still runs in real-time. |

|
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T. Barron, Aleksander Holynski CVPR, 2025 (Oral Presentation) project page / arXiv An approach for turning a video into a 4D radiance field that can be rendered in real-time. When combined with a text-to-video model, this enables text-to-4D. |

|
Generative Multiview Relighting for
3D Reconstruction under Extreme Illumination Variation
Hadi Alzayer, Philipp Henzler, Jonathan T. Barron, Jia-Bin Huang, Pratul P. Srinivasan, Dor Verbin CVPR, 2025 (Highlight) project page / arXiv Images taken under extreme illumination variation can be made consistent with diffusion, and this enables high-quality 3D reconstruction. |

|
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Alex Trevithick, Roni Paiss, Philipp Henzler, Dor Verbin, Rundi Wu, Hadi Alzayer, Ruiqi Gao, Ben Poole, Jonathan T. Barron, Aleksander Holynski, Ravi Ramamoorthi, Pratul P. Srinivasan CVPR, 2025 project page / arXiv Simulating the world with video models lets you make inconsistent captures consistent. |
|
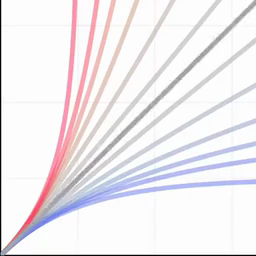
A Power Transform
Jonathan T. Barron arXiv, 2025 tweet / arXiv A slight tweak to the Box-Cox power transform generalizes a variety of curves, losses, kernel functions, probability distributions, bump functions, and neural network activation functions. |

|
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Ruiqi Gao*, Aleksander Holynski*, Philipp Henzler, Arthur Brussee, Ricardo Martin Brualla, Pratul P. Srinivasan, Jonathan T. Barron, Ben Poole* NeurIPS, 2024 (Oral Presentation) project page / arXiv A single model built around diffusion and NeRF that does text-to-3D, image-to-3D, and few-view reconstruction, trains in 1 minute, and renders at 60FPS in a browser. |

|
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections
Dor Verbin, Pratul Srinivasan, Peter Hedman, Benjamin Attal, Ben Mildenhall, Richard Szeliski, Jonathan T. Barron SIGGRAPH Asia, 2024 project page / arXiv Carefully casting reflection rays lets us synthesize photorealistic specularities in real-world scenes. |

|
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Benjamin Attal, Dor Verbin, Ben Mildenhall, Peter Hedman, Jonathan T. Barron, Matthew O'Toole, Pratul P. Srinivasan ECCV, 2024 (Oral Presentation) project page / arXiv A more physically-accurate inverse rendering system based on radiance caching for recovering geometry, materials, and lighting from RGB images of an object or scene. |

|
Nuvo: Neural UV Mapping for Unruly 3D Representations
Pratul Srinivasan, Stephan J. Garbin, Dor Verbin, Jonathan T. Barron, Ben Mildenhall ECCV, 2024 project page / video / arXiv Neural fields let you recover editable UV mappings for the challenging geometries produced by NeRF-like models. |

|
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Christian Reiser, Stephan J. Garbin, Pratul Srinivasan, Dor Verbin, Richard Szeliski, Ben Mildenhall, Jonathan T. Barron, Peter Hedman*, Andreas Geiger* SIGGRAPH, 2024 project page / video / arXiv Applying anti-aliasing to a discrete opacity grid lets you render a hard representation into a soft image, and this enables highly-detailed mesh recovery. |

|
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
Daniel Duckworth*, Peter Hedman*, Christian Reiser, Peter Zhizhin, Jean-François Thibert, Mario Lučić, Richard Szeliski, Jonathan T. Barron SIGGRAPH, 2024 (Honorable Mention) project page / video / arXiv Distilling a Zip-NeRF into a tiled set of MERFs lets you fly through radiance fields on laptops and smartphones at 60 FPS. |

|
Eclipse: Disambiguating Illumination and Materials using Unintended Shadows
Dor Verbin, Ben Mildenhall, Peter Hedman, Jonathan T. Barron, Todd Zickler, Pratul Srinivasan CVPR, 2024 (Oral Presentation) project page / video / arXiv Shadows cast by unobserved occluders provide a high-frequency cue for recovering illumination and materials. |

|
ReconFusion: 3D Reconstruction with Diffusion Priors
Rundi Wu*, Ben Mildenhall*, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P. Srinivasan, Dor Verbin, Jonathan T. Barron, Ben Poole, Aleksander Holynski* CVPR, 2024 project page / arXiv Using a multi-image diffusion model as a regularizer lets you recover high-quality radiance fields from just a handful of images. |

|
SHINOBI: Shape and Illumination using Neural Object Decomposition via BRDF Optimization In-the-Wild
Andreas Engelhardt, Amit Raj, Mark Boss, Yunzhi Zhang, Abhishek Kar, Yuanzhen Li, Deqing Sun, Ricardo Martin Brualla, Jonathan T. Barron, Hendrik P.A. Lensch, Varun Jampani CVPR, 2024 project page / video / arXiv A class-agnostic inverse rendering solution for turning in-the-wild images of an object into a relightable 3D asset. |


|
InterNeRF: Scaling Radiance Fields via Parameter Interpolation
Clinton Wang, Peter Hedman, Polina Golland, Jonathan T. Barron, Daniel Duckworth CVPR Neural Rendering Intelligence, 2024 arXiv Parameter interpolation enables high-quality large-scale scene reconstruction and out-of-core training and rendering. |

|
State of the Art on Diffusion Models for Visual Computing
Ryan Po, Wang Yifan, Vladislav Golyanik, Kfir Aberman, Jonathan T. Barron, Amit H. Bermano, Eric Ryan Chan, Tali Dekel, Aleksander Holynski, Angjoo Kanazawa, C. Karen Liu, Lingjie Liu, Ben Mildenhall, Matthias Nießner, Björn Ommer, Christian Theobalt, Peter Wonka, Gordon Wetzstein Eurographics State-of-the-Art Report, 2024 A survey of recent progress in diffusion models for images, videos, and 3D. |
|
CamP: Camera Preconditioning for Neural Radiance Fields
Keunhong Park, Philipp Henzler, Ben Mildenhall, Jonathan T. Barron, Ricardo Martin-Brualla SIGGRAPH Asia, 2023 project page / arXiv Preconditioning based on camera parameterization helps NeRF and camera extrinsics/intrinsics optimize better together. |

|
Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul Srinivasan, Peter Hedman ICCV, 2023 (Oral Presentation, Best Paper Finalist) project page / video / arXiv Combining mip-NeRF 360 and grid-based models like Instant NGP lets us reduce error rates by 8%–77% and accelerate training by 24x. |

|
DreamBooth3D: Subject-Driven Text-to-3D Generation
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan T. Barron, Yuanzhen Li, Varun Jampani ICCV, 2023 project page / arXiv Combining DreamBooth (personalized text-to-image) and DreamFusion (text-to-3D) yields high-quality, subject-specific 3D assets with text-driven modifications |

|
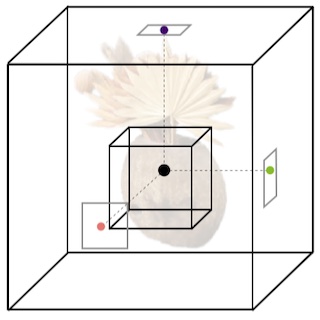
BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
Lior Yariv*, Peter Hedman*, Christian Reiser, Dor Verbin, Pratul Srinivasan, Richard Szeliski, Jonathan T. Barron, Ben Mildenhall SIGGRAPH, 2023 project page / video / arXiv We use SDFs to bake a NeRF-like model into a high quality mesh and do real-time view synthesis. |
|
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Christian Reiser, Richard Szeliski, Dor Verbin, Pratul Srinivasan, Ben Mildenhall, Andreas Geiger, Jonathan T. Barron, Peter Hedman SIGGRAPH, 2023 project page / video / arXiv We use volumetric rendering with a sparse 3D feature grid and 2D feature planes to do real-time view synthesis. |
 
|
AligNeRF: High-Fidelity Neural Radiance Fields via Alignment-Aware Training
Yifan Jiang, Peter Hedman, Ben Mildenhall, Dejia Xu, Jonathan T. Barron, Zhangyang Wang, Tianfan Xue CVPR, 2023 project page / arXiv Accounting for misalignment due to scene motion or calibration errors improves NeRF reconstruction quality. |

|
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall ICLR, 2023 (Oral Presentation, Outstanding Paper Award) project page / arXiv / gallery We optimize a NeRF from scratch using a pretrained text-to-image diffusion model to do text-to-3D generative modeling. |
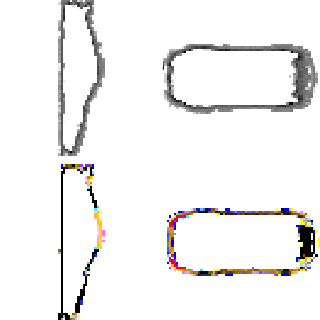 
|
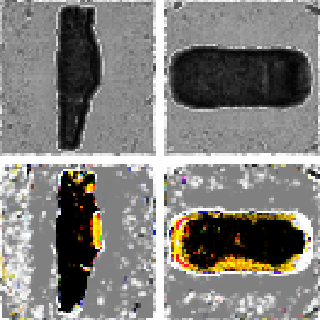
Learning a Diffusion Prior for NeRFs
Guandao Yang, Abhijit Kundu, Leonidas J. Guibas, Jonathan T. Barron, Ben Poole ICLR Workshop, 2023 Training a diffusion model on grid-based NeRFs lets you (conditionally) sample NeRFs. |
|
MIRA: Mental Imagery for Robotic Affordances
Lin Yen-Chen, Pete Florence, Andy Zeng, Jonathan T. Barron, Yilun Du, Wei-Chiu Ma, Anthony Simeonov, Alberto Rodriguez, Phillip Isola CoRL, 2022 NeRF lets us synthesize novel orthographic views that work well with pixel-wise algorithms for robotic manipulation. |
 
|
SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image Collections
Mark Boss, Andreas Engelhardt, Abhishek Kar, Yuanzhen Li, Deqing Sun, Jonathan T. Barron, Hendrik P. A. Lensch, Varun Jampani NeurIPS, 2022 project page / video / arXiv A joint optimization framework for estimating shape, BRDF, camera pose, and illumination from in-the-wild image collections. |
 
|
Polynomial Neural Fields for Subband Decomposition
Guandao Yang*, Sagie Benaim*, Varun Jampani, Kyle Genova, Jonathan T. Barron, Thomas Funkhouser, Bharath Hariharan, Serge Belongie NeurIPS, 2022 Representing neural fields as a composition of manipulable and interpretable components lets you do things like reason about frequencies and scale. |
 
|
Fast and High-Quality Image Denoising via Malleable Convolutions
Yifan Jiang, Bartlomiej Wronski, Ben Mildenhall, Jonathan T. Barron, Zhangyang Wang, Tianfan Xue ECCV, 2022 project page / arXiv We denoise images efficiently by predicting spatially-varying kernels at low resolution and using a fast fused op to jointly upsample and apply these kernels at full resolution. |

|
NeRF-Supervision: Learning Dense Object Descriptors from Neural Radiance Fields
Lin Yen-Chen, Pete Florence, Jonathan T. Barron, Tsung-Yi Lin, Alberto Rodriguez, Phillip Isola ICRA, 2022 project page / arXiv / video / code / colab NeRF works better than RGB-D cameras or multi-view stereo when learning object descriptors. |

|
Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T. Barron, Pratul Srinivasan CVPR, 2022 (Oral Presentation, Best Student Paper Honorable Mention) project page / arXiv / video Explicitly modeling reflections in NeRF produces realistic shiny surfaces and accurate surface normals, and lets you edit materials. |

|
Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul Srinivasan, Peter Hedman CVPR, 2022 (Oral Presentation) project page / arXiv / video mip-NeRF can be extended to produce realistic results on unbounded scenes. |

|
NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images
Ben Mildenhall, Peter Hedman, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T. Barron CVPR, 2022 (Oral Presentation) project page / arXiv / video Properly training NeRF on raw camera data enables HDR view synthesis and bokeh, and outperforms multi-image denoising. |

|
RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
Michael Niemeyer, Jonathan T. Barron, Ben Mildenhall, Mehdi S. M. Sajjadi, Andreas Geiger, Noha Radwan CVPR, 2022 (Oral Presentation) project page / arXiv / video Regularizing unseen views during optimization enables view synthesis from as few as 3 input images. |

|
Block-NeRF: Scalable Large Scene Neural View Synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul Srinivasan, Jonathan T. Barron, Henrik Kretzschmar CVPR, 2022 (Oral Presentation) project page / arXiv / video We can do city-scale reconstruction by training multiple NeRFs with millions of images. |

|
HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
Chung-Yi Weng, Brian Curless, Pratul Srinivasan, Jonathan T. Barron, Ira Kemelmacher-Shlizerman CVPR, 2022 (Oral Presentation) project page / arXiv / video Combining NeRF with pose estimation lets you use a monocular video to do free-viewpoint rendering of a human. |

|
Urban Radiance Fields
Konstantinos Rematas, Andrew Liu, Pratul P. Srinivasan, Jonathan T. Barron, Andrea Tagliasacchi, Tom Funkhouser, Vittorio Ferrari CVPR, 2022 project page / arXiv / video Incorporating lidar and explicitly modeling the sky lets you reconstruct urban environments. |
 
|
Dense Depth Priors for Neural Radiance Fields from Sparse Input Views
Barbara Roessle, Jonathan T. Barron, Ben Mildenhall, Pratul Srinivasan, Matthias Nießner CVPR, 2022 arXiv / video Dense depth completion techniques applied to freely-available sparse stereo data can improve NeRF reconstructions in low-data regimes. |

|
Zero-Shot Text-Guided Object Generation with Dream Fields
Ajay Jain, Ben Mildenhall, Jonathan T. Barron, Pieter Abbeel, Ben Poole CVPR, 2022 project page / arXiv / video Supervising the CLIP embeddings of NeRF renderings lets you to generate 3D objects from text prompts. |
|
Advances in Neural Rendering
Ayush Tewari, Justus Thies, Ben Mildenhall, Pratul Srinivasan, Edgar Tretschk, Yifan Wang, Christoph Lassner, Vincent Sitzmann, Ricardo Martin-Brualla, Stephen Lombardi, Tomas Simon, Christian Theobalt, Matthias Niessner, Jonathan T. Barron, Gordon Wetzstein, Michael Zollhoefer, Vladislav Golyanik State of the Art Report at EUROGRAPHICS, 2022 A survey of recent progress in neural rendering. |
 
|
Neural-PIL: Neural Pre-Integrated Lighting for Reflectance Decomposition
Mark Boss, Varun Jampani, Raphael Braun, Ce Liu, Jonathan T. Barron, Hendrik P. A. Lensch NeurIPS, 2021 project page / video / arXiv Replacing a costly illumination integral with a simple network query enables more accurate novel view-synthesis and relighting compared to NeRD. |

|
HyperNeRF: A Higher-Dimensional Representation
for Topologically Varying Neural Radiance Fields
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, Steven M. Seitz SIGGRAPH Asia, 2021 project page / arXiv Applying ideas from level set methods to NeRF lets you represent scenes that deform and change shape. |
 
|
NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination Xiuming Zhang, Pratul Srinivasan, Boyang Deng, Paul Debevec, William T. Freeman, Jonathan T. Barron SIGGRAPH Asia, 2021 project page / arXiv / video By placing priors on illumination and materials, we can recover NeRF-like models of the intrinsics of a scene from a single multi-image capture. |
|
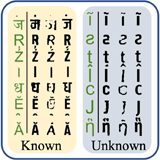
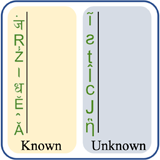
Scalable Font Reconstruction with Dual Latent Manifolds
Nikita Srivatsan, Si Wu, Jonathan T. Barron, Taylor Berg-Kirkpatrick EMNLP, 2021 VAEs can be used to disentangle a font's style from its content, and to generalize to characters that were never observed during training. |
|
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, Pratul Srinivasan ICCV, 2021 (Oral Presentation, Best Paper Honorable Mention) project page / arXiv / video / code NeRF is aliased, but we can anti-alias it by casting cones and prefiltering the positional encoding function. |

|
Baking Neural Radiance Fields for Real-Time View Synthesis
Peter Hedman, Pratul Srinivasan, Ben Mildenhall, Jonathan T. Barron, Paul Debevec ICCV, 2021 (Oral Presentation) project page / arXiv / video / demo Baking a trained NeRF into a sparse voxel grid of colors and features lets you render it in real-time in your browser. |

|
Nerfies: Deformable Neural Radiance Fields
Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, Ricardo-Martin Brualla ICCV, 2021 (Oral Presentation) project page / arXiv / video Building deformation fields into NeRF lets you capture non-rigid subjects, like people. |
 
|
Cross-Camera Convolutional Color Constancy
Mahmoud Afifi, Jonathan T. Barron, Chloe LeGendre, Yun-Ta Tsai, Francois Bleibel ICCV, 2021 (Oral Presentation) With some extra (unlabeled) test-set images, you can build a hypernetwork that calibrates itself at test time to previously-unseen cameras. |
 
|
Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Shumian Xin, Neal Wadhwa, Tianfan Xue, Jonathan T. Barron, Pratul Srinivasan, Jiawen Chen, Ioannis Gkioulekas, Rahul Garg ICCV, 2021 (Oral Presentation) project page / code Multiplane images can be used to simultaneously deblur dual-pixel images, despite variable defocus due to depth variation in the scene. |

|
NeRD: Neural Reflectance Decomposition from Image Collections
Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Barron, Ce Liu, Hendrik P. A. Lensch ICCV, 2021 project page / video / code / arXiv A NeRF-like model that can decompose (and mesh) objects with non-Lambertian reflectances, complex geometry, and unknown illumination. |
 
|
How to Train Neural Networks for Flare Removal
Yicheng Wu, Qiurui He, Tianfan Xue, Rahul Garg, Jiawen Chen, Ashok Veeraraghavan, Jonathan T. Barron ICCV, 2021 project page / arXiv Simulating the optics of a camera's lens lets you train a model that removes lens flare from a single image. |

|
iNeRF: Inverting Neural Radiance Fields for Pose Estimation
Lin Yen-Chen, Pete Florence, Jonathan T. Barron, Alberto Rodriguez, Phillip Isola, Tsung-Yi Lin IROS, 2021 project page / arXiv / video Given an image of an object and a NeRF of that object, you can estimate that object's pose. |

|
IBRNet: Learning Multi-View Image-Based Rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, Thomas Funkhouser CVPR, 2021 project page / code / arXiv By learning how to pay attention to input images at render time, we can amortize inference for view synthesis and reduce error rates by 15%. |

|
NeRV: Neural Reflection and Visibility Fields for Relighting and View Synthesis
Pratul Srinivasan, Boyang Deng, Xiuming Zhang, Matthew Tancik, Ben Mildenhall, Jonathan T. Barron CVPR, 2021 project page / video / arXiv Using neural approximations of expensive visibility integrals lets you recover relightable NeRF-like models. |

|
Learned Initializations for Optimizing Coordinate-Based Neural Representations
Matthew Tancik*, Ben Mildenhall*, Terrance Wang, Divi Schmidt, Pratul Srinivasan, Jonathan T. Barron, Ren Ng CVPR, 2021 (Oral Presentation) project page / video / arXiv Using meta-learning to find weight initializations for coordinate-based MLPs allows them to converge faster and generalize better. |

|
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
Ricardo Martin-Brualla*, Noha Radwan*, Mehdi S. M. Sajjadi*, Jonathan T. Barron, Alexey Dosovitskiy, Daniel Duckworth CVPR, 2021 (Oral Presentation) project page / arXiv / video Letting NeRF reason about occluders and appearance variation produces photorealistic view synthesis using only unstructured internet photos. |
 
|
Learned Dual-View Reflection Removal
Simon Niklaus, Xuaner (Cecilia) Zhang, Jonathan T. Barron, Neal Wadhwa, Rahul Garg, Feng Liu, Tianfan Xue WACV, 2021 project page / arXiv Reflections and the things behind them often exhibit parallax, and this lets you remove reflections from stereo pairs. |

|
Neural Light Transport for Relighting and View Synthesis
Xiuming Zhang, Sean Fanello, Yun-Ta Tsai, Tiancheng Sun, Tianfan Xue, Rohit Pandey, Sergio Orts-Escolano, Philip Davidson, Christoph Rhemann, Paul Debevec, Jonathan T. Barron, Ravi Ramamoorthi, William T. Freeman ACM TOG, 2021 project page / arXiv / video Embedding a convnet within a predefined texture atlas enables simultaneous view synthesis and relighting. |
|
Light Stage Super-Resolution: Continuous High-Frequency Relighting
Tiancheng Sun, Zexiang Xu Xiuming Zhang, Sean Fanello, Christoph Rhemann, Paul Debevec, Yun-Ta Tsai, Jonathan T. Barron, Ravi Ramamoorthi SIGGRAPH Asia, 2020 project page / arXiv Scans for light stages are inherently aliased, but we can use learning to super-resolve them. |
 
|
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
Matthew Tancik*, Pratul Srinivasan*, Ben Mildenhall*, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, Ren Ng NeurIPS, 2020 (Spotlight) project page / video: 3 min, 10 min / arXiv / code Composing neural networks with a simple Fourier feature mapping allows them to learn detailed high-frequency functions. |
|
A Generalization of Otsu's Method and Minimum Error Thresholding
Jonathan T. Barron ECCV, 2020 (Spotlight) code / video / bibtex A simple and fast Bayesian algorithm that can be written in ~10 lines of code outperforms or matches giant CNNs on image binarization, and unifies three classic thresholding algorithms. |
 
|
What Matters in Unsupervised Optical Flow
Rico Jonschkowski, Austin Stone, Jonathan T. Barron, Ariel Gordon, Kurt Konolige, Anelia Angelova ECCV, 2020 (Oral Presentation) code Extensive experimentation yields a simple optical flow technique that is trained on only unlabeled videos, but still works as well as supervised techniques. |

|
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Ben Mildenhall*, Pratul Srinivasan*, Matthew Tancik*, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng ECCV, 2020 (Oral Presentation, Best Paper Honorable Mention, CACM Research Highlight) project page / arXiv / talk video / supp video / code / CACM (foreward) Training a tiny non-convolutional neural network to reproduce a scene using volume rendering achieves photorealistic view synthesis. |
 
|
Portrait Shadow Manipulation
Xuaner (Cecilia) Zhang, Jonathan T. Barron, Yun-Ta Tsai, Rohit Pandey, Xiuming Zhang, Ren Ng, David E. Jacobs SIGGRAPH, 2020 project page / video Networks can be trained to remove shadows cast on human faces and to soften harsh lighting. |
 
|
Learning to Autofocus
Charles Herrmann, Richard Strong Bowen, Neal Wadhwa, Rahul Garg, Qiurui He, Jonathan T. Barron, Ramin Zabih CVPR, 2020 project page / arXiv Machine learning can be used to train cameras to autofocus (which is not the same problem as "depth from defocus"). |

|
Lighthouse: Predicting Lighting Volumes for Spatially-Coherent Illumination
Pratul Srinivasan*, Ben Mildenhall*, Matthew Tancik, Jonathan T. Barron, Richard Tucker, Noah Snavely CVPR, 2020 project page / code / arXiv / video We predict a volume from an input stereo pair that can be used to calculate incident lighting at any 3D point within a scene. |
 
|
Sky Optimization: Semantically Aware Image Processing of Skies in Low-Light Photography
Orly Liba, Longqi Cai, Yun-Ta Tsai, Elad Eban, Yair Movshovitz-Attias, Yael Pritch, Huizhong Chen, Jonathan T. Barron NTIRE CVPRW, 2020 project page If you want to photograph the sky, it helps to know where the sky is. |
 
|
Handheld Mobile Photography in Very Low Light
Orly Liba, Kiran Murthy, Yun-Ta Tsai, Timothy Brooks, Tianfan Xue, Nikhil Karnad, Qiurui He, Jonathan T. Barron, Dillon Sharlet, Ryan Geiss, Samuel W. Hasinoff, Yael Pritch, Marc Levoy SIGGRAPH Asia, 2019 project page By rethinking metering, white balance, and tone mapping, we can take pictures in places too dark for humans to see clearly. |
 
|
A Deep Factorization of Style and Structure in Fonts
Nikita Srivatsan, Jonathan T. Barron, Dan Klein, Taylor Berg-Kirkpatrick EMNLP, 2019 (Oral Presentation) Variational auto-encoders can be used to disentangle a characters style from its content. |
|
Learning Single Camera Depth Estimation using Dual-Pixels
Rahul Garg, Neal Wadhwa, Sameer Ansari, Jonathan T. Barron ICCV, 2019 (Oral Presentation) code / bibtex Considering the optics of dual-pixel image sensors improves monocular depth estimation techniques. |
 
|
Single Image Portrait Relighting
Tiancheng Sun, Jonathan T. Barron, Yun-Ta Tsai, Zexiang Xu, Xueming Yu, Graham Fyffe, Christoph Rhemann, Jay Busch, Paul Debevec, Ravi Ramamoorthi SIGGRAPH, 2019 project page / arxiv / video / press / bibtex Training a neural network on light stage scans and environment maps produces an effective relighting method. |
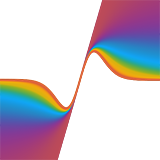 
|
A General and Adaptive Robust Loss Function
Jonathan T. Barron CVPR, 2019 (Oral Presentation, Best Paper Award Finalist) arxiv / supplement / video / talk / slides / code: TF, JAX, pytorch / reviews / bibtex A single robust loss function is a superset of many other common robust loss functions, and allows training to automatically adapt the robustness of its own loss. |
 
|
Pushing the Boundaries of View Extrapolation with Multiplane Images
Pratul P. Srinivasan, Richard Tucker, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng, Noah Snavely CVPR, 2019 (Oral Presentation, Best Paper Award Finalist) supplement / video / bibtex View extrapolation with multiplane images works better if you reason about disocclusions and disparity sampling frequencies. |
 
|
Unprocessing Images for Learned Raw Denoising
Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, Jonathan T. Barron CVPR, 2019 (Oral Presentation) arxiv / project page / code / bibtex We can learn a better denoising model by processing and unprocessing images the same way a camera does. |
 
|
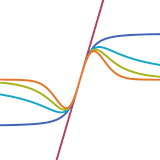
Learning to Synthesize Motion Blur
Tim Brooks, Jonathan T. Barron CVPR, 2019 (Oral Presentation) arxiv / supplement / project page / video / code / bibtex Frame interpolation techniques can be used to train a network that directly synthesizes linear blur kernels. |
|
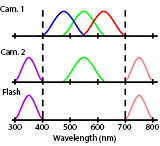
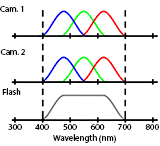
Stereoscopic Dark Flash for Low-light Photography
Jian Wang, Tianfan Xue, Jonathan T. Barron, Jiawen Chen ICCP, 2019 By making one camera in a stereo pair hyperspectral we can multiplex dark flash pairs in space instead of time. |
 
|
Depth from Motion for Smartphone AR
Julien Valentin, Adarsh Kowdle, Jonathan T. Barron, Neal Wadhwa, and others SIGGRAPH Asia, 2018 planar filter toy code / bibtex Depth cues from camera motion allow for real-time occlusion effects in augmented reality applications. |
 
|
Synthetic Depth-of-Field with a Single-Camera Mobile Phone
Neal Wadhwa, Rahul Garg, David E. Jacobs, Bryan E. Feldman, Nori Kanazawa, Robert Carroll, Yair Movshovitz-Attias, Jonathan T. Barron, Yael Pritch, Marc Levoy SIGGRAPH, 2018 arxiv / blog post / bibtex Dual pixel cameras and semantic segmentation algorithms can be used for shallow depth of field effects. This system is the basis for "Portrait Mode" on the Google Pixel 2 smartphones |
 
|
Aperture Supervision for Monocular Depth Estimation
Pratul P. Srinivasan, Rahul Garg, Neal Wadhwa, Ren Ng, Jonathan T. Barron CVPR, 2018 code / bibtex Varying a camera's aperture provides a supervisory signal that can teach a neural network to do monocular depth estimation. |
 
|
Burst Denoising with Kernel Prediction Networks
Ben Mildenhall, Jonathan T. Barron, Jiawen Chen, Dillon Sharlet, Ren Ng, Robert Carroll CVPR, 2018 (Spotlight) supplement / code / bibtex We train a network to predict linear kernels that denoise noisy bursts from cellphone cameras. |
|
A Hardware-Friendly Bilateral Solver for Real-Time Virtual Reality Video
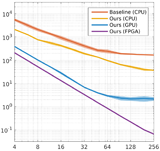
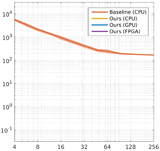
Amrita Mazumdar, Armin Alaghi, Jonathan T. Barron, David Gallup, Luis Ceze, Mark Oskin, Steven M. Seitz High-Performance Graphics (HPG), 2017 project page A reformulation of the bilateral solver can be implemented efficiently on GPUs and FPGAs. |
 
|
Deep Bilateral Learning for Real-Time Image Enhancement
Michaël Gharbi, Jiawen Chen, Jonathan T. Barron, Samuel W. Hasinoff, Frédo Durand SIGGRAPH, 2017 project page / video / bibtex / press By training a deep network in bilateral space we can learn a model for high-resolution and real-time image enhancement. |
 
|
Fast Fourier Color Constancy
Jonathan T. Barron, Yun-Ta Tsai, CVPR, 2017 video / bibtex / code / output / blog post / press Color space can be aliased, allowing white balance models to be learned and evaluated in the frequency domain. This improves accuracy by 13-20% and speed by 250-3000x. This technology is used by Google Pixel, Google Photos, and Google Maps. |

|
Jump: Virtual Reality Video
Robert Anderson, David Gallup, Jonathan T. Barron, Janne Kontkanen, Noah Snavely, Carlos Hernández, Sameer Agarwal, Steven M Seitz SIGGRAPH Asia, 2016 supplement / video / bibtex / blog post Using computer vision and a ring of cameras, we can make video for virtual reality headsets that is both stereo and 360°. This technology is used by Jump. |
|
Burst Photography for High Dynamic Range and Low-Light Imaging on Mobile Cameras
Samuel W. Hasinoff, Dillon Sharlet, Ryan Geiss, Andrew Adams, Jonathan T. Barron, Florian Kainz, Jiawen Chen, Marc Levoy SIGGRAPH Asia, 2016 project page / supplement / bibtex Mobile phones can take beautiful photographs in low-light or high dynamic range environments by aligning and merging a burst of images. This technology is used by the Nexus HDR+ feature. |
 
|
The Fast Bilateral Solver
Jonathan T. Barron, Ben Poole ECCV, 2016 (Oral Presentation, Best Paper Honorable Mention) arXiv / bibtex / video (they messed up my slides, use →) / keynote (or PDF) / code / depth super-res results / reviews Our solver smooths things better than other filters and faster than other optimization algorithms, and you can backprop through it. |
 
|
Geometric Calibration for Mobile, Stereo, Autofocus Cameras
Stephen DiVerdi, Jonathan T. Barron WACV, 2016 bibtex Standard techniques for stereo calibration don't work for cheap mobile cameras. |
 
|
Semantic Image Segmentation with Task-Specific Edge Detection Using CNNs and a Discriminatively Trained Domain Transform
CVPR, 2016 Liang-Chieh Chen, Jonathan T. Barron, George Papandreou, Kevin Murphy, Alan L. Yuille bibtex / project page / code By integrating an edge-aware filter into a convolutional neural network we can learn an edge-detector while improving semantic segmentation. |
 
|
Convolutional Color Constancy
Jonathan T. Barron ICCV, 2015 supplement / bibtex / video (or mp4) By framing white balance as a chroma localization task we can discriminatively learn a color constancy model that beats the state-of-the-art by 40%. |

|
Scene Intrinsics and Depth from a Single Image
Evan Shelhamer, Jonathan T. Barron, Trevor Darrell ICCV Workshop, 2015 bibtex The monocular depth estimates produced by fully convolutional networks can be used to inform intrinsic image estimation. |

|
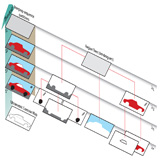
Fast Bilateral-Space Stereo for Synthetic Defocus
Jonathan T. Barron, Andrew Adams, YiChang Shih, Carlos Hernández CVPR, 2015 (Oral Presentation) abstract / supplement / bibtex / talk / keynote (or PDF) By embedding a stereo optimization problem in "bilateral-space" we can very quickly solve for an edge-aware depth map, letting us render beautiful depth-of-field effects. This technology is used by the Google Camera "Lens Blur" feature. |
|
Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation
Jordi Pont-Tuset, Pablo Arbeláez, Jonathan T. Barron, Ferran Marqués, Jitendra Malik TPAMI, 2017 project page / bibtex / fast eigenvector code We produce state-of-the-art contours, regions and object candidates, and we compute normalized-cuts eigenvectors 20× faster. This paper subsumes our CVPR 2014 paper. |

|
Shape, Illumination, and Reflectance from Shading
We present SIRFS, which can estimate shape, chromatic illumination, reflectance, and shading from a single image of an masked object. This paper subsumes our CVPR 2011, CVPR 2012, and ECCV 2012 papers. |
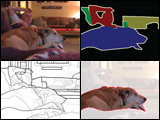
|
Multiscale Combinatorial Grouping
Pablo Arbeláez, Jordi Pont-Tuset, Jonathan T. Barron, Ferran Marqués, Jitendra Malik CVPR, 2014 project page / bibtex This paper is subsumed by our journal paper. |
|
Volumetric Semantic Segmentation using Pyramid Context Features
Jonathan T. Barron, Pablo Arbeláez, Soile V. E. Keränen, Mark D. Biggin, David W. Knowles, Jitendra Malik ICCV, 2013 supplement / poster / bibtex / video 1 (or mp4) / video 2 (or mp4) / code & data We present a technique for efficient per-voxel linear classification, which enables accurate and fast semantic segmentation of volumetric Drosophila imagery. |
|

|
3D Self-Portraits
Hao Li, Etienne Vouga, Anton Gudym, Linjie Luo, Jonathan T. Barron, Gleb Gusev SIGGRAPH Asia, 2013 video / shapify.me / bibtex Our system allows users to create textured 3D models of themselves in arbitrary poses using only a single 3D sensor. |

|
Intrinsic Scene Properties from a Single RGB-D Image
Jonathan T. Barron, Jitendra Malik CVPR, 2013 (Oral Presentation) supplement / bibtex / talk / keynote (or powerpoint, PDF) / code & data By embedding mixtures of shapes & lights into a soft segmentation of an image, and by leveraging the output of the Kinect, we can extend SIRFS to scenes.
|

|
Boundary Cues for 3D Object Shape Recovery
Kevin Karsch, Zicheng Liao, Jason Rock, Jonathan T. Barron, Derek Hoiem CVPR, 2013 supplement / bibtex Boundary cues (like occlusions and folds) can be used for shape reconstruction, which improves object recognition for humans and computers. |
|
Color Constancy, Intrinsic Images, and Shape Estimation
Jonathan T. Barron, Jitendra Malik ECCV, 2012 supplement / bibtex / poster / video This paper is subsumed by SIRFS. |
|


|
Shape, Albedo, and Illumination from a Single Image of an Unknown Object
Jonathan T. Barron, Jitendra Malik CVPR, 2012 supplement / bibtex / poster This paper is subsumed by SIRFS. |

|
A Category-Level 3-D Object Dataset: Putting the Kinect to Work
Allison Janoch, Sergey Karayev, Yangqing Jia, Jonathan T. Barron, Mario Fritz, Kate Saenko, Trevor Darrell ICCV 3DRR Workshop, 2011 bibtex / "smoothing" code We present a large RGB-D dataset of indoor scenes and investigate ways to improve object detection using depth information. |

|
High-Frequency Shape and Albedo from Shading using Natural Image Statistics
Jonathan T. Barron, Jitendra Malik CVPR, 2011 bibtex This paper is subsumed by SIRFS. |
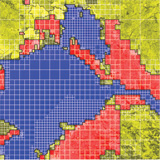
|
Discovering Efficiency in Coarse-To-Fine Texture Classification
Jonathan T. Barron, Jitendra Malik Technical Report, 2010 bibtex A model and feature representation that allows for sub-linear coarse-to-fine semantic segmentation. |

|
Parallelizing Reinforcement Learning
Jonathan T. Barron, Dave Golland, Nicholas J. Hay Technical Report, 2009 bibtex Markov Decision Problems which lie in a low-dimensional latent space can be decomposed, allowing modified RL algorithms to run orders of magnitude faster in parallel. |

|
Blind Date: Using Proper Motions to Determine the Ages of Historical Images
Jonathan T. Barron, David W. Hogg, Dustin Lang, Sam Roweis The Astronomical Journal, 136, 2008 Using the relative motions of stars we can accurately estimate the date of origin of historical astronomical images. |

|
Cleaning the USNO-B Catalog Through Automatic Detection of Optical Artifacts
Jonathan T. Barron, Christopher Stumm, David W. Hogg, Dustin Lang, Sam Roweis The Astronomical Journal, 135, 2008 We use computer vision techniques to identify and remove diffraction spikes and reflection halos in the USNO-B Catalog. In use at Astrometry.net |
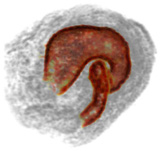

Miscellanea |
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |